
Introduction
In the previous blog-post — A Quick Review of Coreference Resolution Task, we covered the basic terms of the coreference task. In this blog-post we will go into detail about the development of coreference models in the recent years.
Coreference Models
There are four main types of coreference models:
1. Rule-Based Models
2. Mention-Pair Models
3. Mention-Ranking Models
4. Clustering-Based Models
Let’s go over each one and explain it!
1. Rule-Based Models
At 1976 Jerry Hobbs wrote a naive algorithm on coreference resolution. The problem with Hobbs rule-based attitude was that the rules couldn’t capture both cases like the examples below:
“She poured water from the pitcher into the cup until it was full”
“She poured water from the pitcher into the cup until it was empty”
While in the first one “it” refers to the “cup” and in the second one “it” refers to the “pitcher”. It will work just for one of them.
2. Mention-Pair Models
The second kind of coreference model is a binary classifier. The idea is to train a classifier that will find the probability of two mentions to be coreferent. It will compare between each two mentions in the sentence and will assign their probability to be connected. The ideal condition will be that negative examples will receive a probability that is closed to 0 and positive examples will be close to 1.

The model uses cross entropy loss for its training. The test will get a sentence and a set of mentions and it will predict for each two if they are coreferent or not. In the end of the procedure it will add coreference links between mention pairs that are above some threshold. It can also add transitive links and it will create the clusters.

Local vs Global Features
Mention pair scores alone are not enough to produce a final set of coreference clusters because they do not enforce transitivity.
The primary weakness of this approach is that it only relies on local information to make decisions, so it can not consolidate information at the entity level.
For example, let’s take a look at the sentence:
Hillary Clinton and Bill Clinton left the white house. Clinton said: “I don’t know when we will come back”. He didn’t want to talk about journey”.
A cluster may consist of [Hillary Clinton, Clinton, He] because the coreference decision between Hillary Clinton and Clinton is made independently from the one between Clinton and He.
Using entity-level information is valuable because it allows early coreference decisions to inform later ones. For example, finding that Clinton and he corefer makes it more likely that Clinton corefers with Bill Clinton than Hillary Clinton due to gender agreement constraints.
We could have solve it by looking at the global cluster level that could have rejected this coreference link, because of the inconsistency in the cluster level.
3. Mention-Ranking Models
The mention-ranking model assigns a score to each pair of candidate antecedent and corefernts. In the end of the procedure the model will choose just one of the pairs (even though there might be more in the text).
The problem with this method is the difficulty to deal with singelton mentions. The solution for that can be a dummy NA mention that allows the model to leave the mention without any link.
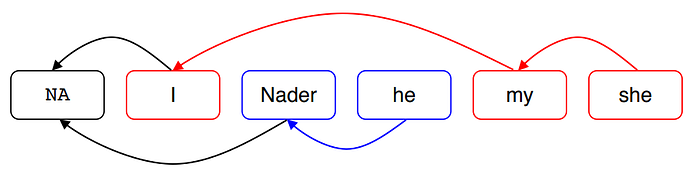
For example, what is the best antecedent to the word ‘my’ in the sentence:
“I want to watch this movie again because it is one of my favorites’? she said”.
The candidate preceding mentions can be: “I”, “it”, “movie”. We will add to this list also a NA option, because there is a chance that it is a new referent.
Each of those mention pairs gets a score from the model and the pair that receives the best score will be joined together. The same as mention-pair model except each mention is assigned only one antecedent.


As a result of the sequence of many local decisions of referents that were linked together, a global structure (cluster) will be created:
Mathematically it will look like the term below:
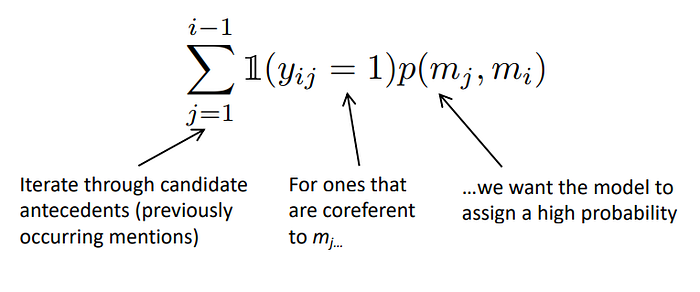
Mj is our current mention and Mi is the candidate antecedent, while we will want to maximize the probability between them. In the training level it will be part of the loss function that we will try to optimize:
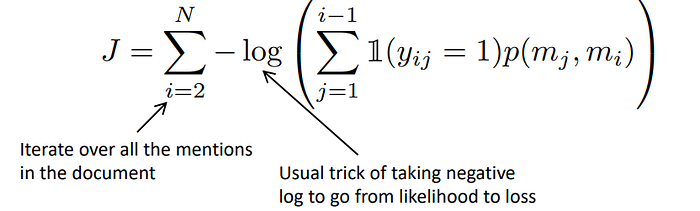
There are few ways to compute the coreferent probabilities between Mi and Mj:
- Non-Neural Statistical Classifier
- Simple Neural Network
- Advanced Models using LSTMs, Attention
1. Non-Neural Statistical Classifier
Feature-based systems that use Hobss’ algorithm as a feature inside that is doing the coreference links in the sentence.
2. Simple Neural Network
A neural mention-pair model is just a standard deep feed forward NN. This NN uses pretrained word embedding features and categorical features as an input to capture similarities between the candidate antecedent and the mention. It has 3 hidden layers and ReLU functions at every level that outputs the score of how likely is it to be coreferant.
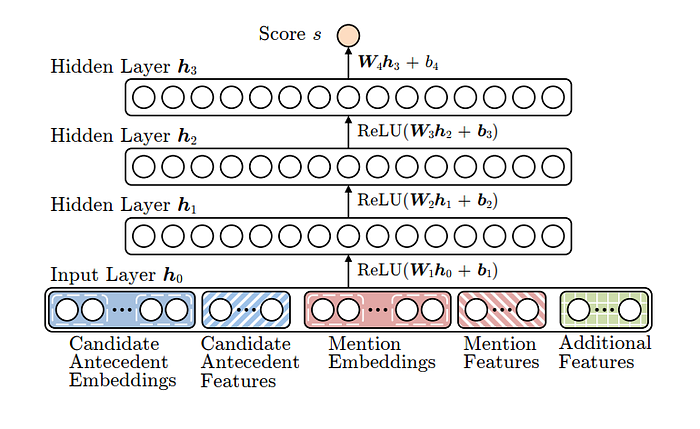
What are the features that the network uses? In traditional models the amount of hand-crafted features (such as recency, speakers, distance etc) were more common but with time the use of those features reduced. Today it uses a combination of word embedding and the statistics-based features that reflects the grammatical relation of the mention (is it a subject or an object?).
This model will be trained to classify right and wrong examples; but, it will not be optimal because there are some mistakes that matter more than others. For instance, the example below can mix between two different clusters and it is a really severe mistake. ‘He’ coreferent with ‘Bil Clinton’ and ‘Clinton’ coreferent with ‘He’. ‘Hillary’ coreferent with ‘Clinton’ and ‘Her’ with ‘Hillary’. But if the Two Clintons will by mistake be coreferent it will wrongly connect between the entities and will create one big cluster instead.
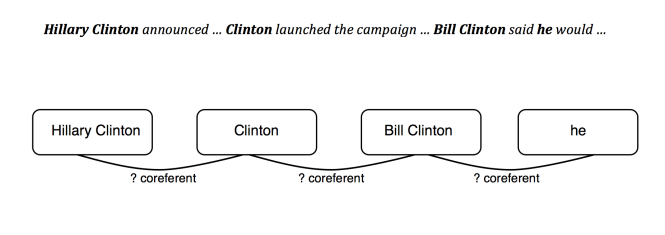
However, in the sentence:
“It was wonderful party, but afterwards the house was dirty, because it was full of people.”
In this example, it will be a mistake to corefer between “house” and the first “it” that doesn’t refer to any word. But, this mistake doesn’t need to bother us like the previous one because it will not effect the understanding of the sentence.
We want that our model will know how to deal with those mistakes and will treat differently major and minor errors (an ideal problem for reinforcement learning that the reward function counts the quality of the clustering).
3. Advanced Models using LSTMs, Attention
End-to-end Neural Coreference Resolution
Another attitude is a model that produces an end-to-end coreference resolution system that receives words as an input and outputs the coreference decisions.
The previous approach — In the classical methods that were presented before, the first step was using a mention detection for entity recognition (e.g; NER, POS tagger etc), and than mention clustering to split them into few different groups. The problem with those methods is that like every pipeline it can lead to an error cascading and effect the model’s performance.
End-to-End approach — The idea behind the end-to-end neural coreference network is that external resources such as parsers and taggers are not required. The network gets the text as an input, process the data all the way until the end, and outputs the corefernce.
This model improves the simple feed-forward NN by using mechanisms as LSTM and attention, packing all the pipeline under one model (without separating the model into two sub models of mention detection and mention clustering). It also considers every sequence of words (span) up to a certain length as a candidate mention. This attitude was proposed for the first time in End-to-end Neural Coreference Resolution paper that was published at 2017.
So, How it works?
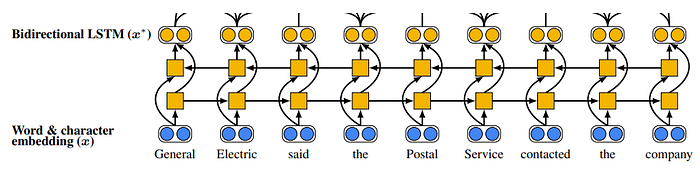
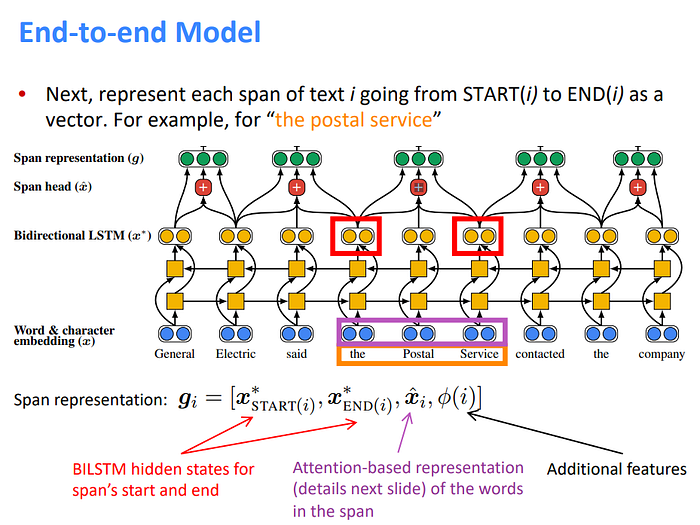
1.Word & character embedding
First, let’s assume vector representations of each word{x1, . . . ,xT}, which are composed of fixed pretrained word embeddings and 1-dimensional convolution neural networks (CNN) over characters that are concatenated together to represent each token.

2. Bidirectional LSTM
The second step is computing vector representations of each span by running a deep bidirectional LSTMs over the document to encode every word in the context.
3. Span representation
The next step is representing each span (a sub-sequence of words) of text as a vector.
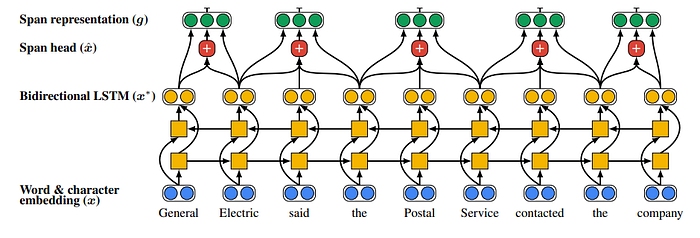
The span representation is composed of few parts:

The first two are the hidden states of the BILSTM of the first and the last word of the span.
The third part is the attention-based representation of the words in the span, which means that in this part the model will find the “head” words in the span. It will calculate αt, which is the attention score for each word using dot product between the weight and the hidden state of the word vector at t timestamp (the output of the Bidirectional LSTMs).

And then it calculates ai,t. It takes all the attention scores for each one of the words from the previous step and puts them in a softmax function that will calculate the weights. Those weights reflects how important this word is in this span.
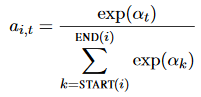
In the end, it calculates the weighted sum of words in this span while a higher weight will be given to the key words of the mention. For example, if we will take the span “the postal service”, the headword will be “service”.
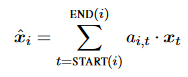
The forth and last part in the span representation is just additional features.
All the above span information is concatenated in the end to produce the final representation gi of span i.
After we found the representation of each span we will use it to check if two spans are coreferent using the following equation of S(i,j):
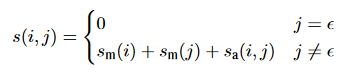
S(i,j) is a pairwise score for a coreferent link between span i and span j. This score sums up three factors:
- Sm(i) indicate whether span i is a mention.
- Sm(j) indicates whether span j is a mention.
- Sa(j,i) indicates whether j is an antecedent of i.
For the calculation of each factor a feed-forward NN is used. It receives the span representation as an input and its output will be multiplied by a weight factor.
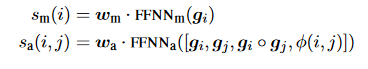
Parameters explanation for the equation above:
· : denotes the dot product.
◦ : denotes element-wise multiplication.
FFNN : denotes a feed-forward neural network
The goal is to learn a distribution P(yi) for each span i, while yi is a set of antecedent assignments:
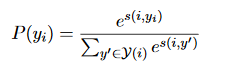
The Disadvantage of this model — Computational challenge:

- O(T2) — The number of spans in a document to consider (T is the number of words).
2. O(T4) — Coreference links to consider (runtime).
The solution for that is using pruning, which is mention detection algorithm that will cut the number of spans that will be considered in the calculations (just those which are more likely to be mentions). It is still considered as an end-to-end model even if in practice we will need to use a mention detector to make it work. The reason for that is that the loss function is defined as end-to-end for the whole procedure.
Higher-order Coreference Resolution with Coarse-to-fine Inference
In 2018, the authors of the paper End-to-end Neural Coreference Resolution proposed an improvement to the end-to-end model used in the paper Higher-order Coreference Resolution with Coarse-to-fine Inference.
They introduce two additions to their previous paper:
- Higher-order Coreference Resolution — The end-to-end model is a first-order model, since it only compares pairs of spans and thus it is based on many independent decisions that can cause to many failures in the final prediction (as we saw before when we examined the differences between local and global features). Using higher-order coreference that uses global features can solve this problem.
2. Coarse-to-fine Inference — An addition of the coarse factor to the pairwise scoring function that enables an extra pruning and reduces the computations.
SpanBERT: Improving Pre-training by Representing and Predicting Spans
SpanBERT is a self-supervised pretraining method designed to better represent and predict spans of text.
This approach extends BERT by:
- Masking random contiguous spans, rather than random individual tokens.
- Using the span boundary objective (SBO) — which tries to predict the entire masked span using only the representations of the tokens at the span’s boundary.
- SpanBERT samples a single contiguous segment of text for each training example (instead of two), and thus does not use BERT’s next sentence prediction task, which was omitted.
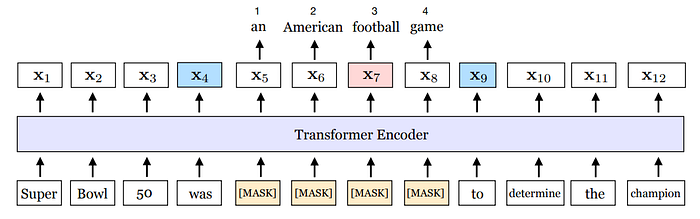
The illustration above details the SpanBERT training level. The span an American football game is masked. The span boundary objective (SBO) uses the output representations of the boundary tokens, x4 and x9 (in blue), to predict each token in the masked span. The equation shows the MLM and SBO loss terms for predicting the token, football (in pink), which as marked by the position embedding p3, is the third token from x4.
4. Clustering-Based Models
This attitude uses clustering algorithm for the coreference task (which is really intuitive because it is a clustering task).
In the paper that was published at 2016 Improving Coreference Resolution by Learning Entity-Level Distributed Representations Clark & Manning used this approach. They proposed an algorithm that starts with a singelton cluster to each mention and in each step it merges a pair of clusters if it predicts they are representing the same entity.
Sometimes mention-pair decisions can be hard for the model to make the coreferent decision and we can explain it by some example:
Bill → Bill Gates — An easy example for coreferent
Google → Google corp — A hard example for coreferent because we can have a case like that which can be correct to for corefernt:
Google → ? Google drive
But cluster-pair decisions can be much more easier for the algorithm. The idea is to make the easy decisions first so the transitive link will be easier later for the decision because we will have more examples in the cluster that will be used to make the mention decision. It will be easier to link between Google and Google Company first and between Google drive and “the product” and then to check if those two clusters are need to be merged is easy because product and company are two different completely things.
They initially created mention-pair representations and used those representations to create cluster-pair representations. The cluster representations will enable to make better coreferent decisions as it builds up clusters of mentions believed to refer to the same entity.
For example, the system could reject linking [Hillary Clinton] with [Clinton, he] because of the low score between the pair (Hillary Clinton, he).

End Notes
If you want to try to run some experiments in this domain, most of them are conducted on CoNLL-2012 dataset. The state-of-the-art for now is SpanBERT: Improving Pre-training by Representing and Predicting Spans that achieved avg F1 score of 79.6.
References
[https://arxiv.org/pdf/1707.07045.pdf]
[https://arxiv.org/pdf/1804.05392.pdf]
[https://arxiv.org/pdf/1606.01323.pdf]
[http://web.stanford.edu/class/cs224n/]
[https://www.aclweb.org/anthology/S15-1034.pdf]
[https://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture16-coref.pdf]
